
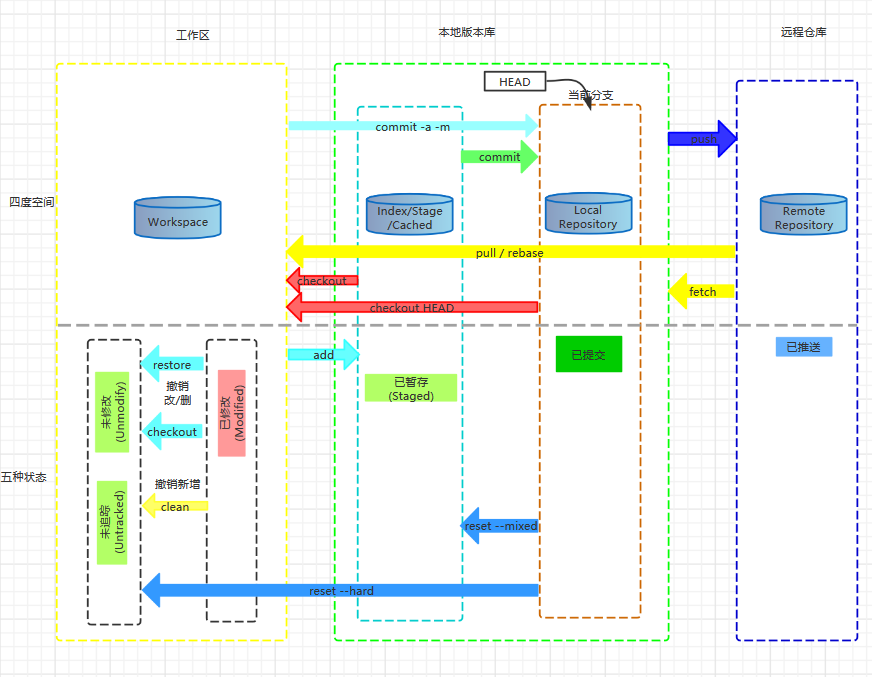
基本概念
四度空间:
工作区:Workspace
就是你在电脑里能看到的目录
暂存区: Index/Stage/Cached
英文叫stage, 或index。一般存放在 “.git目录下” 下的index文件(.git/index)中,所以我们把暂存区有时也叫作索引(index)
版本库:Repository
工作区有一个隐藏目录.git,这个不算工作区,而是Git的版本库。
远程仓库: Remote Repository
远程仓库则被设置在一个能被所有团队成员访问到的远程服务器上,基本上都是在互联网上或者是本地局域网中
五种状态:
未修改(Unmodify):
记录在工作区,没有被修改的文件
未追踪(Untracked):
新增的文件的状态,未受Git管理,记录在工作区
已修改(Modified):
受Git管理过的文件的改动状态(包括改动内容、删除文件),记录在工作区
已暂存(Staged):
将记录在工作区的文件变动状态通知了Git,记录在暂存区
已提交(Commited):
已提交到本地仓库
已推送(pushed):
已推送到远程仓库
一张图概括:
新建一个仓库
git init #在当前目录新建一个git仓库
git clone #clone一个远程的仓库到当前目录
当你创建一个带有.git文件夹的目录后,这个目录中的所有操作都将会被git记录,这就故事开始的地方,让我们开启这个游戏!
加入暂存区
这个目录就是被git记录的工作区,在这个目录下的所有增删改都会被git纳入到版本控制.
可以使用git status查看当前目录的哪些文件的变化:
git status #查看当前工作区文件状态
git status -s #简短形式输出当前工作状态
修改完后使用git add 加入到缓存区.
git add . #将当前目录所有文件做修改都加入缓存区
git add <file name> #将某个文件的修改就如缓存区
如果有操作想被git忽略有3钟种方式:
.gitignore文件
.gitignore只会忽略尚未加入版本控制的文件,如果文件已被加入版本控制,写入.gitignore文件git仍会记录文件的变化.如果已经纳入版本控制的文件想忽略,例如:在远程服务器中的配置文件,想本地修改,又不想被git记录可以使用下面两种命令
git update-index --assume-unchanged
git update-index --assume-unchanged <file name> # 这个会关闭文件与远程仓库的跟踪,认为这个文件远程仓库是不会修改,所以每次pull都是本地的文件
反向操作
git update-index --no-assume-unchanged <file name>
git update-index --skip-worktree
git update-index --skip-worktree <file name> # 这个不会关闭文件与远程仓库的跟踪,只是告诉Git不要跟踪对本地文件/文件夹的更改,每次pull时会拉取最新的变化会提示冲突,但因为没有跟踪本地更改,所以需要no-skip-worktree再合并最新的变化 或者使用git stash将本地的更改保存起来,再git pull,然后再git stash pop,再合并冲突,比较麻烦
反向操作:
git update-index --no-skip-worktree <file name>
提交
改写提交
如果提交完发现自己漏提了文件,或者提交信息写错了可以使用--amend来改写提交
git commit --amend #如果有漏提的文件,add到缓存区即可,然后git会打开默认的编辑器让你重新编写提交信息
复制提交
cherry-pick可以将其它提交复制到当前再提交一遍
执行:
git cherry-pick c2 c4
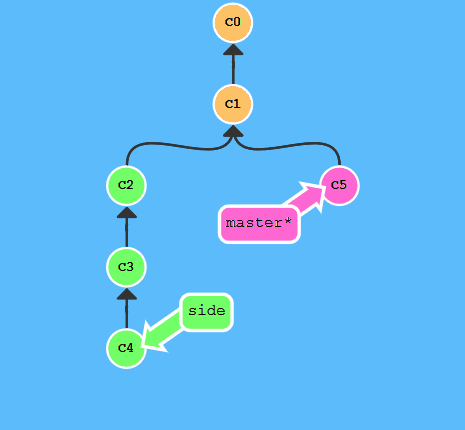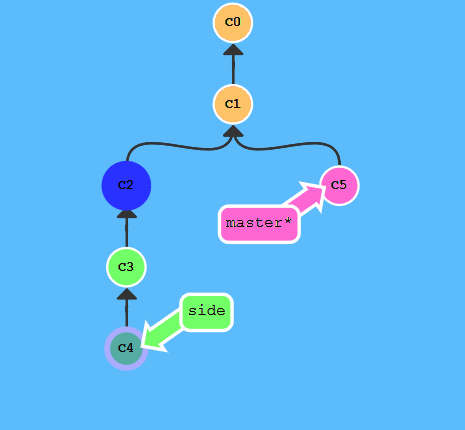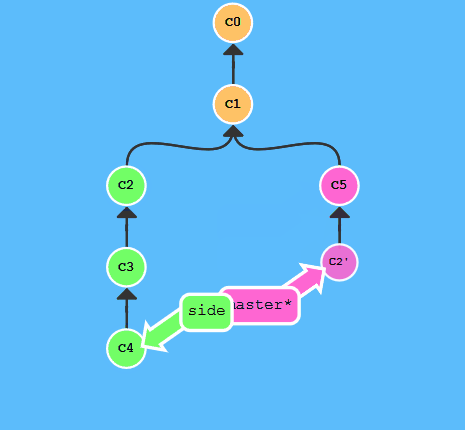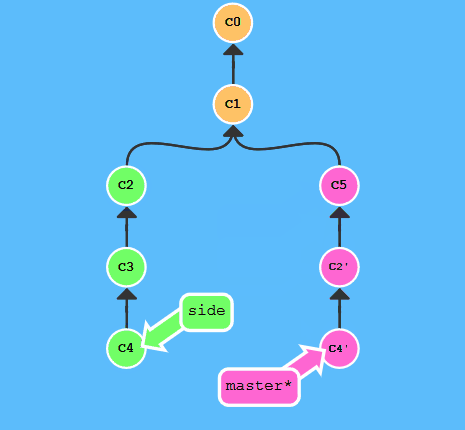
恢复
文件已被修改尚未加入到缓存区
git restore <file name> #将文件恢复到和缓存区(index)一样的状态
文件被修改并提交到缓存区
git restore --staged <file name> #将文件从缓存区(index)移动出来
新增的文件删除(untracked状态)
git clean -f <file name> #将untracked状态的文件删除
Git指针
指针是git的精髓,理解的指针的移动对于很多命令的理解和记忆更胜一筹.
Git中指针大致有五类:
-
HEAD
指向当前正在操作的 commit。 -
分支指针
指向当前分支所在的commit
-
ORIG_HEAD
当使用一些在 Git 看来比较危险的操作去移动 HEAD 指针的时候,ORIG_HEAD 就会被创建出来,记录危险操作之前的 HEAD,方便 HEAD 的恢复,有点像修改前的备份。 -
FETCH_HEAD
记录从远程仓库拉取的记录。 -
MERGE_HEAD
当运行git merge时,MERGE_HEAD 记录你正在合并到你的分支中的提交。MERGE_HEAD在合并的时候会出现,合并结束,就删除了这个文件。 -
CHERRY_PICK_HEAD
记录您在运行git cherry-pick时要合并的提交。同上,这个文件只在 cherry-pick 期间存在。
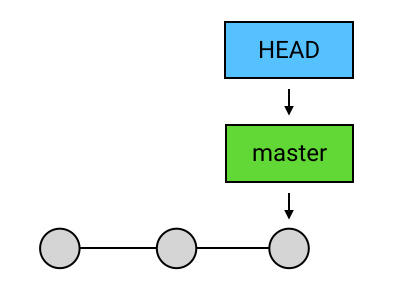
这里我们主要理解HEAD指针和分支指针.
正常情况下HEAD指针是指向当前分支指针,如图:
git checkout <commit id>
git checkout 本质就是移动HEAD指针 (个人理解,待验证)
当执行git checkout <commit id> 或 git checkout HEAD^时,进入指针分离模式,HEAD指针指向一条commit id,不再指向分支指针,此时如果提交代码,只有HEAD指针会指向新提交的commit id,而分支指针不会移动.

此时如果想让HEAD重新指向分支指针,执行git checkout <branch name>即可.
git reset
reset 的本质:移动 HEAD 以及它所指向的 branch
实质上,reset 这个指令虽然可以用来撤销 commit ,但它的实质行为并不是撤销,而是移动 HEAD ,并且「捎带」上 HEAD 所指向的 branch(如果有的话)。也就是说,reset 这个指令的行为其实和它的字面意思 “reset”(重置)十分相符:它是用来重置 HEAD 以及它所指向的 branch 的位置的。
而 reset --hard HEAD^ 之所以起到了撤销 commit 的效果,是因为它把 HEAD 和它所指向的 branch 一起移动到了当前 commit 的父 commit 上,从而起到了「撤销」的效果:
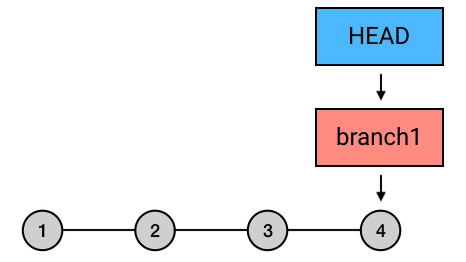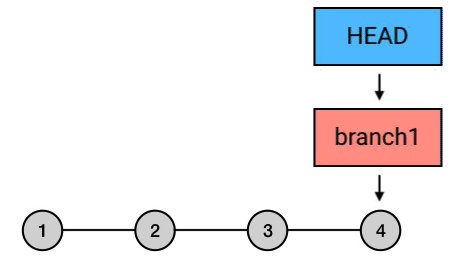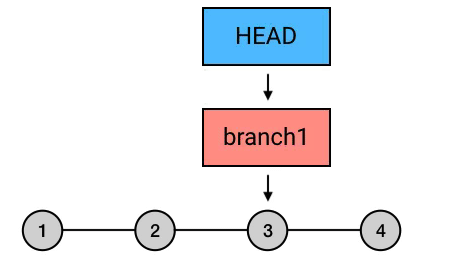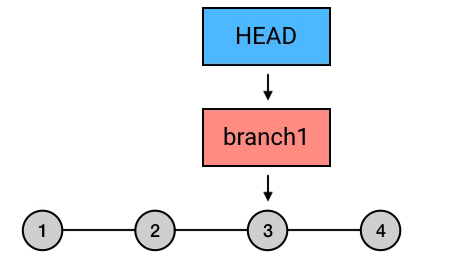
git reset 各个选项解释:
- –soft – 缓存区和工作目录都不会被改变
- –mixed – 默认选项。缓存区和你指定的提交同步,但工作目录不受影响
- –hard – 缓存区和工作目录都同步到你指定的提交
把这些标记想成定义
git reset操作的作用域就容易理解多了。
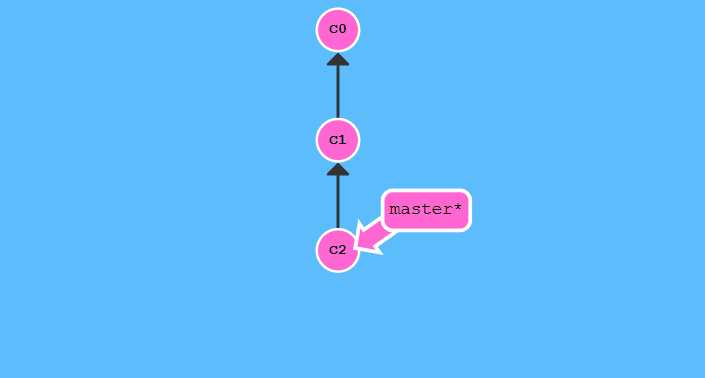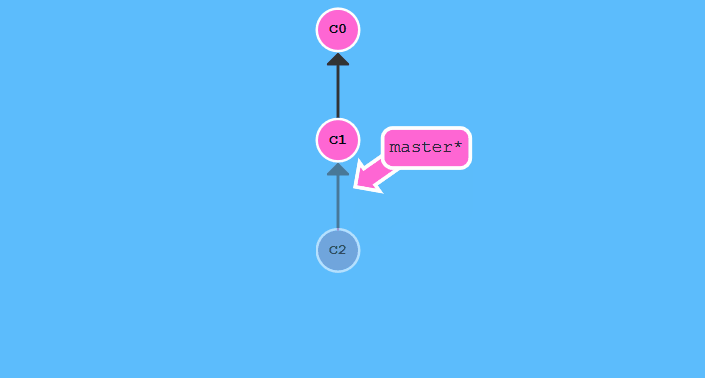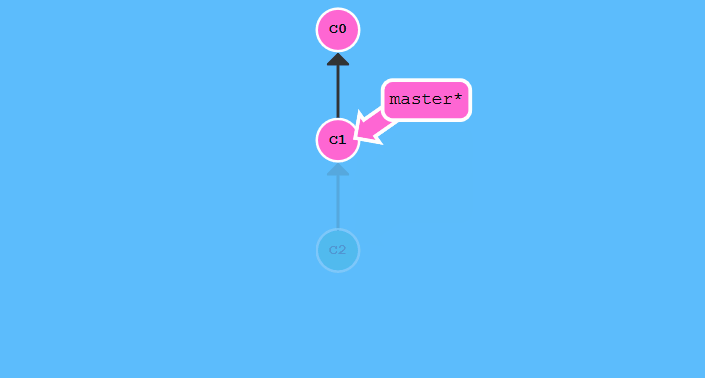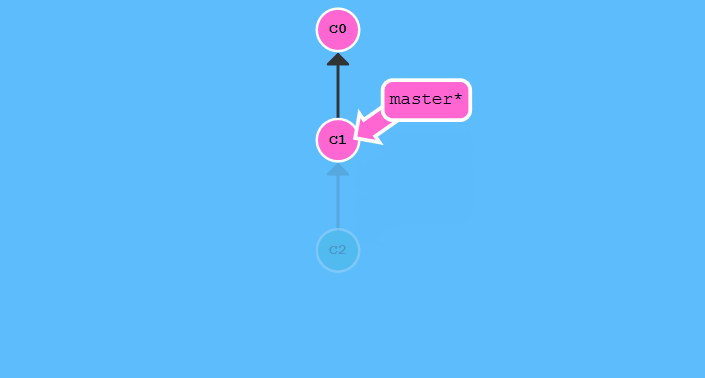
git branch -f <branch name>
这条命令是将分支指针移动到指定位置.运行git branch -f master c1:
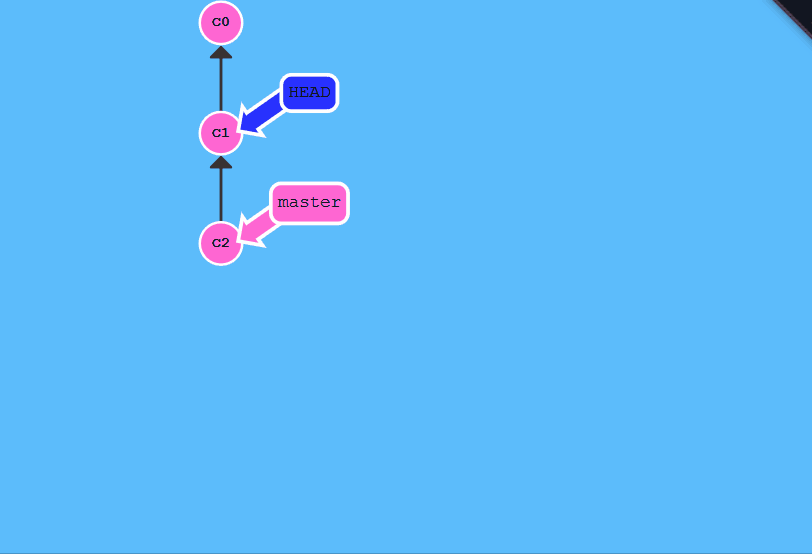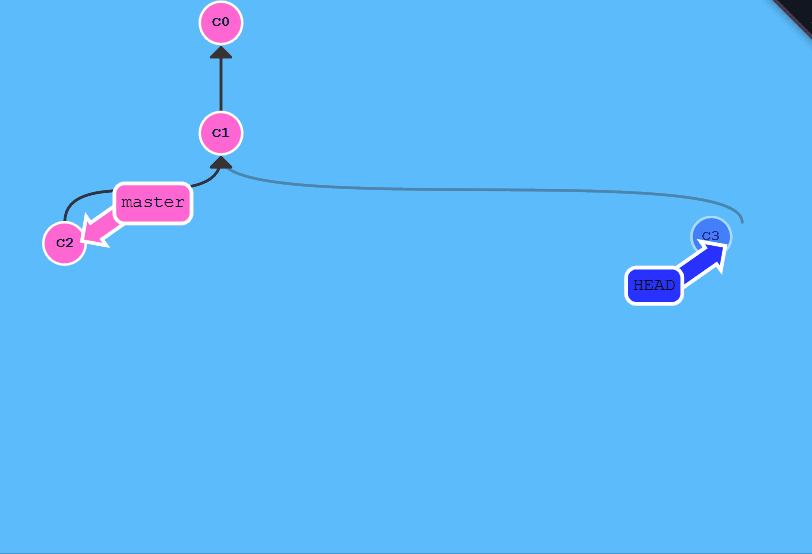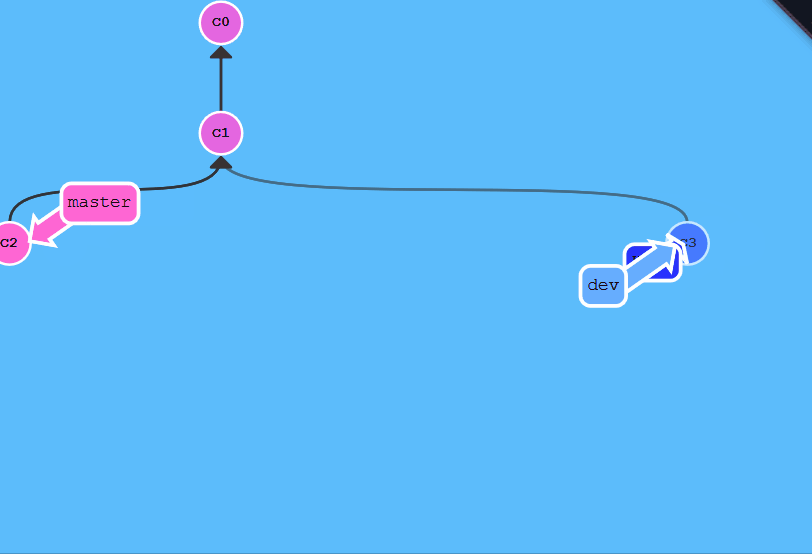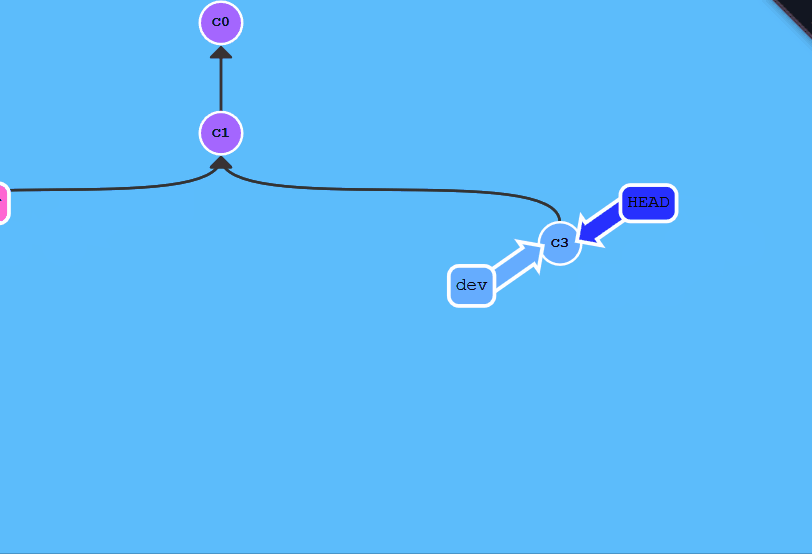
匿名分支与头指针分离处理
- 匿名分支
当git进入头指针分离状态,进行提交会产生一个匿名分支,如果一直匿名分支,就会被git清理掉,
可以使用`git branch ``起个名字,来避免这种情况.
- 强制回退丢失
commit id
如果意外使用如:git reset --hard HEAD^时,可能会使commit消失,这时候可以使用git reflog来找回命令
分支
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。
有人把 Git 的分支模型称为它的“必杀技特性”,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢? Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。 与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。 理解和精通这一特性,你便会意识到 Git 是如此的强大而又独特,并且从此真正改变你的开发方式。
命令
git branch #列出仓库中所有分支。
git branch <branch> #创建一个名为 <branch> 的分支。不会 自动切换到那个分支去。
git branch -d <branch> #删除指定分支。这是一个安全的操作,Git 会阻止你删除包含未合并更改的分支。
git branch -D <branch> #强制删除指定分支,即使包含未合并更改。如果你希望永远删除某条开发线的所有提交,你应该用这个命令。
git branch -m <branch> #将当前分支命名为 <branch>。
git checkout <existing-branch> #查看特定分支,分支应该已经通过 git branch 创建。这使得 <existing-branch> 成为当前的分支,并更新工作目录的版本。
git checkout -b <new-branch> #创建并查看 <new-branch>,-b 选项是一个方便的标记,告诉Git在运行 git checkout <new-branch> 之前运行 git branch <new-branch>。
git checkout -b <new-branch> <existing-branch> #和上一条相同,但将 <existing-branch> 作为新分支的基,而不是当前分支。
分支合并的两种姿势
git merge
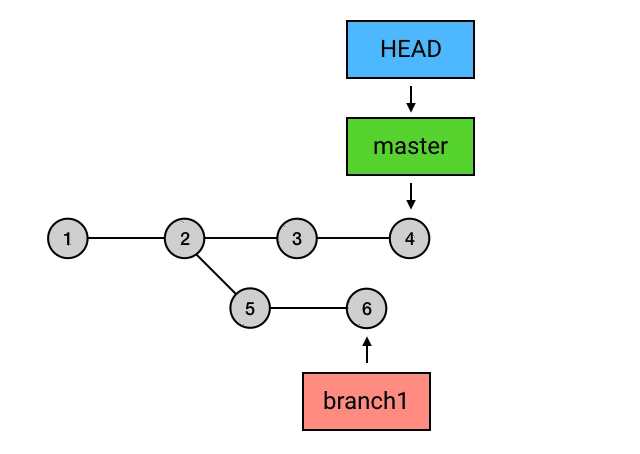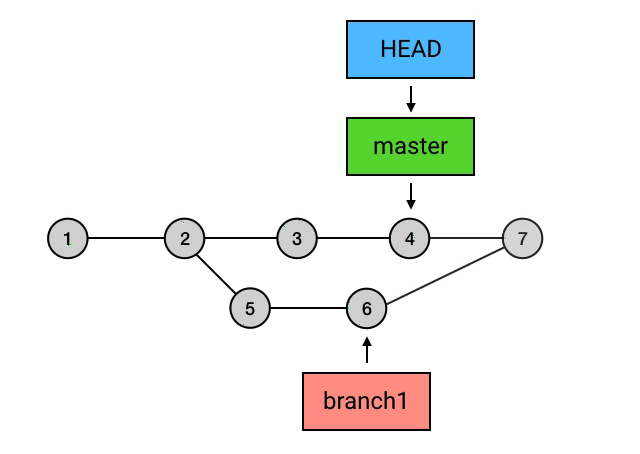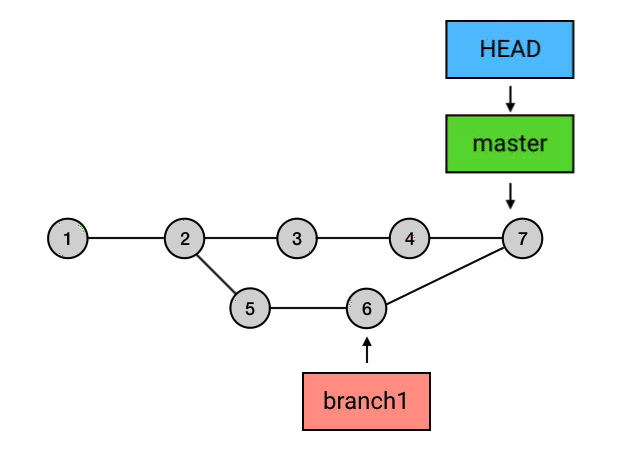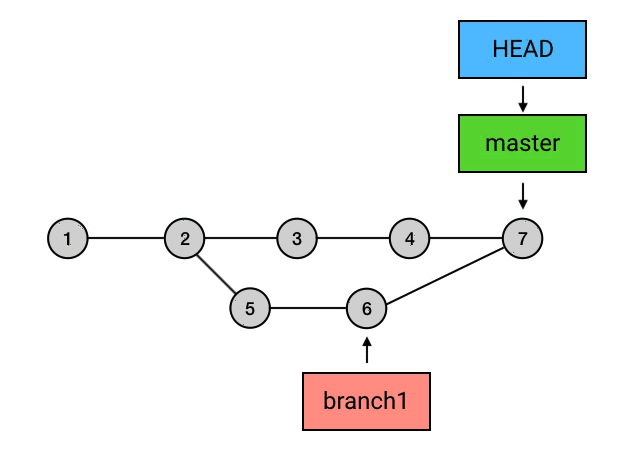
merge的三种特殊情况
-
冲突
merge在做合并的时候,是有一定的自动合并能力的:如果一个分支改了 A 文件,另一个分支改了 B 文件,那么合并后就是既改 A 也改 B,这个动作会自动完成;如果两个分支都改了同一个文件,但一个改的是第 1 行,另一个改的是第 2 行,那么合并后就是第 1 行和第 2 行都改,也是自动完成。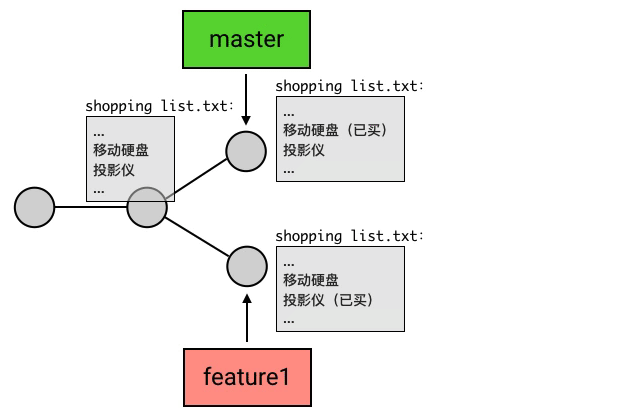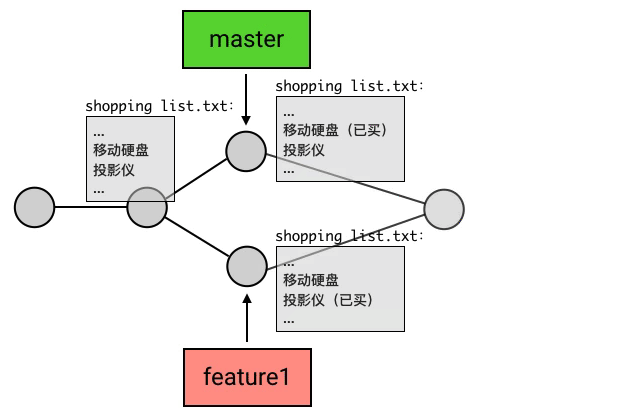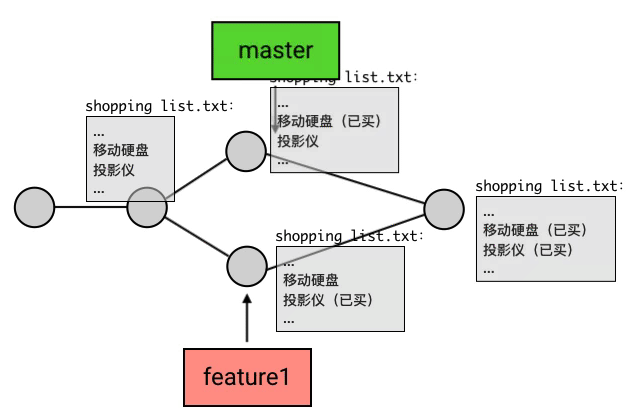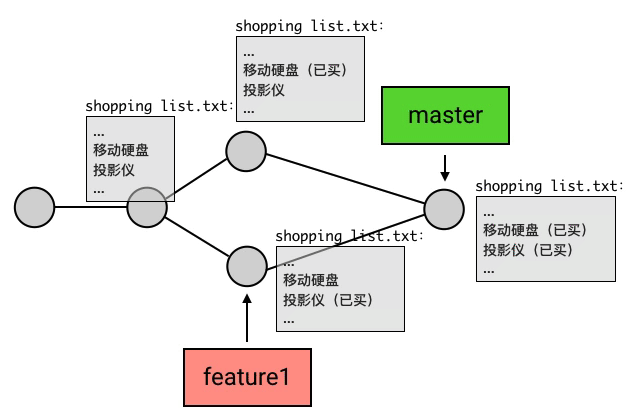
但,如果两个分支修改了同一部分内容,merge 的自动算法就搞不定了。这种情况 Git 称之为:冲突(Conflict)。

解决方法:
- 解决掉冲突
- 手动
commit一下
或者放弃合并:
git merge --abort
-
HEAD 领先于目标 commit
如果
merge时的目标commit和HEAD处的commit并不存在分叉,而是HEAD领先于目标commit:
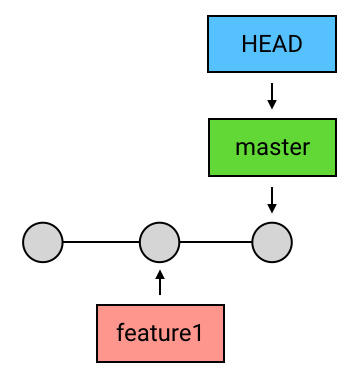
那么 merge 就没必要再创建一个新的 commit 来进行合并操作,因为并没有什么需要合并的。在这种情况下, Git 什么也不会做,merge 是一个空操作。
-
HEAD 落后于 目标 commit——fast-forward
而另一种情况:如果
HEAD和目标commit依然是不存在分叉,但HEAD不是领先于目标commit,而是落后于目标commit.那么 Git 会直接把
HEAD(以及它所指向的branch,如果有的话)移动到目标commit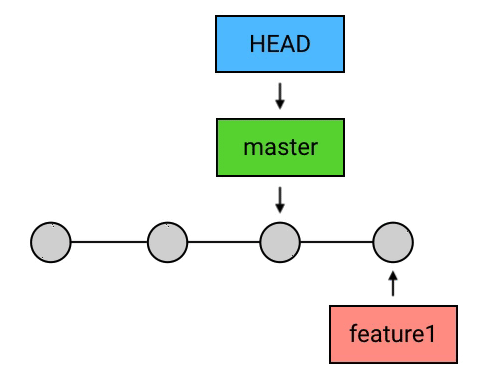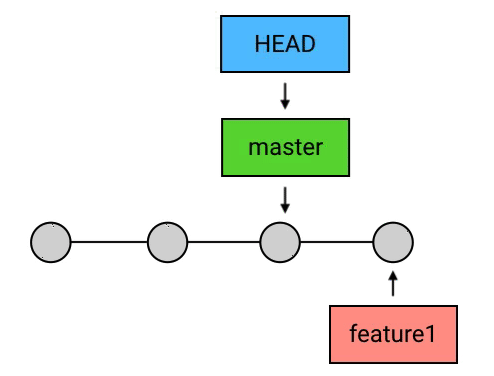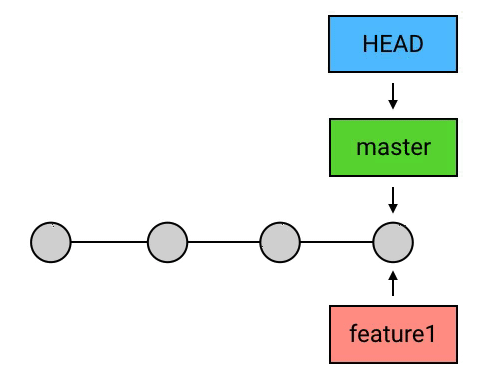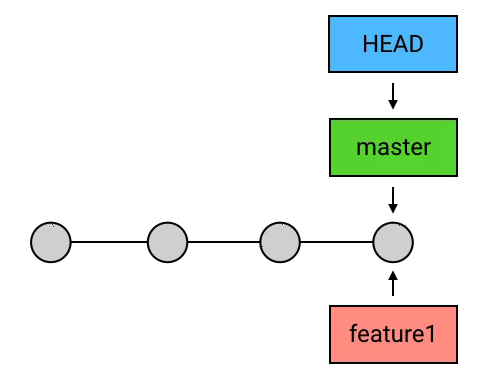
git rebase
rebase 的意思是,给你的 commit 序列重新设置基础点(也就是父 commit)。展开来说就是,把你指定的 commit 以及它所在的 commit 串,以指定的目标 commit 为基础,依次重新提交一次。例如下面这个 merge:
git merge branch1
如果把 merge 换成 rebase,可以这样操作:
git checkout branch1
git rebase master
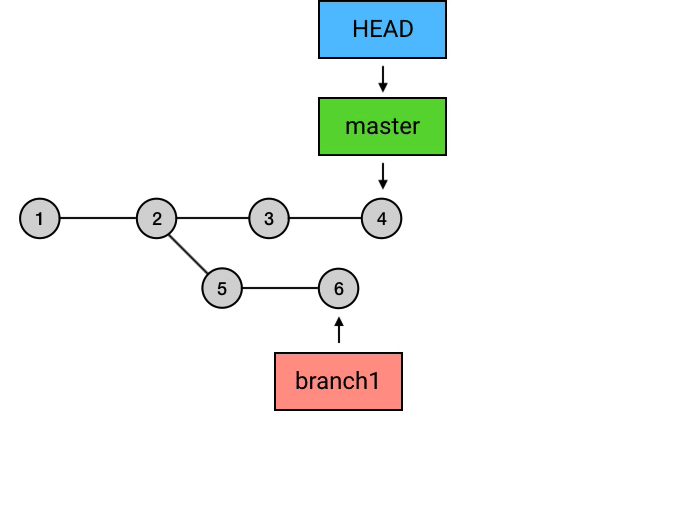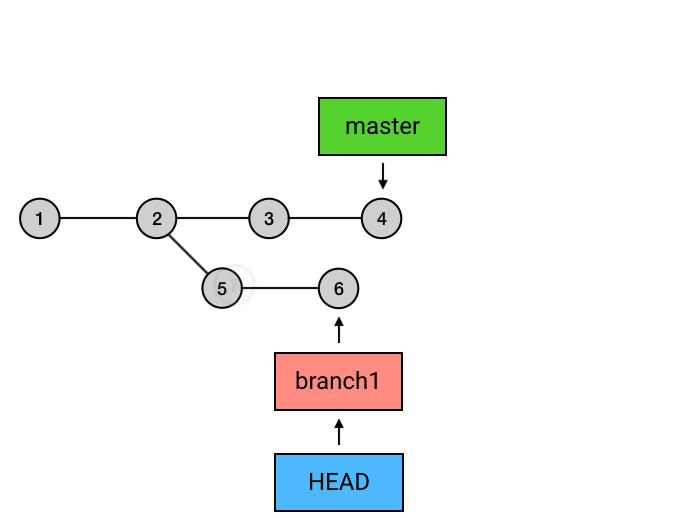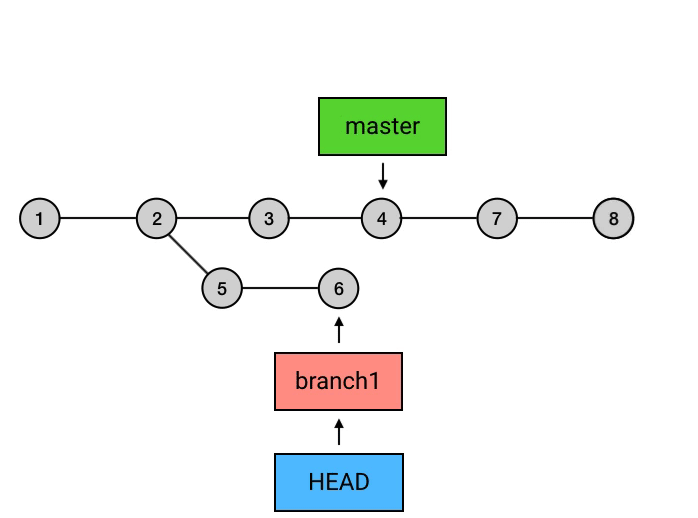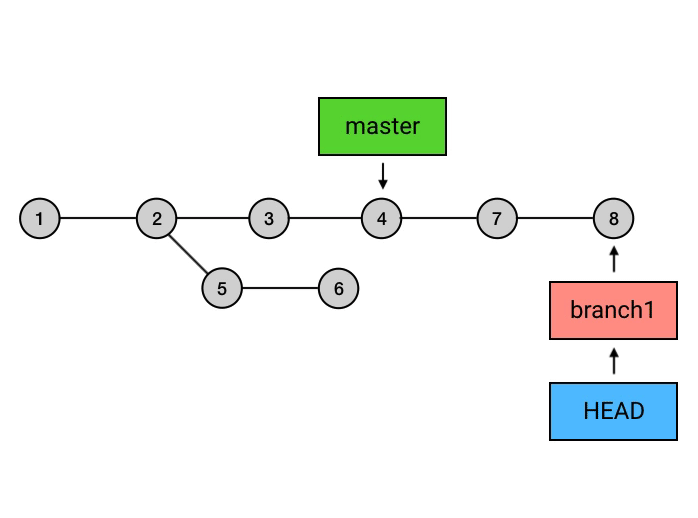
另外,在 rebase 之后,记得切回 master 再 merge 一下,把 master 移到最新的 commit:
git checkout master
git merge branch1
为什么要从
branch1来rebase,然后再切回master再merge一下这么麻烦,而不是直接在master上执行rebase?从图中可以看出,
rebase后的commit虽然内容和rebase之前相同,但它们已经是不同的commits了。如果直接从master执行rebase的话,就会是下面这样:
这就导致
master上之前的两个最新commit被剔除了。如果这两个commit之前已经在中央仓库存在,这就会导致没法push了:

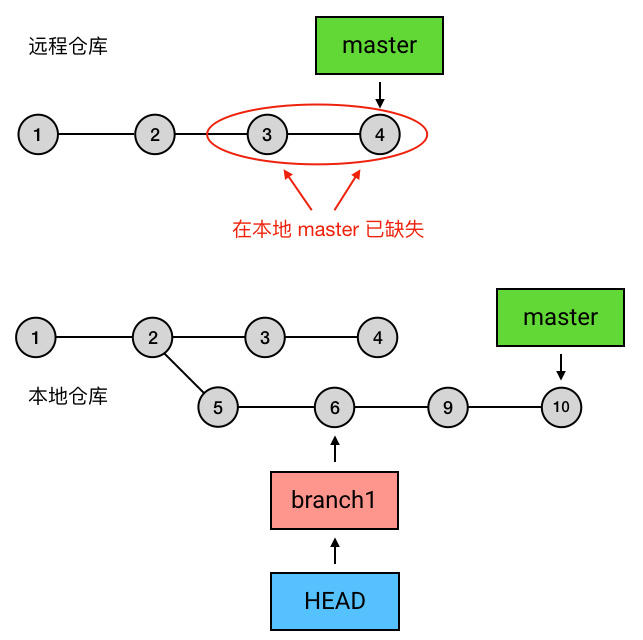
它会把整个 branch1分支移动到 master 分支的后面,有效地把所有 master 分支上新的提交并入过来。但是,rebase 为原分支上每一个提交创建一个新的提交,重写了项目历史,并且不会带来合并提交。
rebase最大的好处是你的项目历史会非常整洁。首先,它不像 git merge 那样引入不必要的合并提交。其次,如上图所示,rebase 导致最后的项目历史呈现出完美的线性——你可以从项目终点到起点浏览而不需要任何的 fork。这让你更容易使用 git log、git bisect 和 gitk 来查看项目历史。
不过,这种简单的提交历史会带来两个后果:安全性和可跟踪性。如果你违反了 rebase 黄金法则,重写项目历史可能会给你的协作工作流带来灾难性的影响。此外,rebase 不会有合并提交中附带的信息——你看不到 branch分支中并入了上游的哪些更改。
交互式rebase
交互式的 rebase 允许你更改并入新分支的提交。这比自动的 rebase 更加强大,因为它提供了对分支上提交历史完整的控制。一般来说,这被用于将 feature 分支并入 master 分支之前,清理混乱的历史。
把 -i 传入 git rebase 选项来开始一个交互式的rebase过程:
git checkout feature
git rebase -i master
它会打开一个文本编辑器,显示所有将被移动的提交:
pick 33d5b7a Message for commit #1
pick 9480b3d Message for commit #2
pick 5c67e61 Message for commit #3
这个列表定义了 rebase 将被执行后分支会是什么样的。更改 pick 命令或者重新排序,这个分支的历史就能如你所愿了。比如说,如果第二个提交修复了第一个提交中的小问题,你可以用 fixup 命令把它们合到一个提交中:
pick 33d5b7a Message for commit #1
fixup 9480b3d Message for commit #2
pick 5c67e61 Message for commit #3
忽略不重要的提交会让你的 feature 分支的历史更清晰易读。这是 git merge 做不到的。
Rebase的黄金法则
当你理解 rebase 是什么的时候,最重要的就是什么时候 不能 用 rebase。git rebase 的黄金法则便是,绝不要在公共的分支上使用它。
这次 rebase 将 master 分支上的所有提交都移到了 feature 分支后面。问题是它只发生在你的代码仓库中,其他所有的开发者还在原来的 master 上工作。因为 rebase 引起了新的提交,Git 会认为你的 master 分支和其他人的 master 已经分叉了。
同步两个 master 分支的唯一办法是把它们 merge 到一起,导致一个额外的合并提交和两堆包含同样更改的提交。不用说,这会让人非常困惑。
所以,在你运行 git rebase 之前,一定要问问你自己「有没有别人正在这个分支上工作?」。如果答案是肯定的,那么把你的爪子放回去,重新找到一个无害的方式(如 git revert)来提交你的更改。不然的话,你可以随心所欲地重写历史。
强制推送
如果你想把 rebase 之后的 master 分支推送到远程仓库,Git 会阻止你这么做,因为两个分支包含冲突。但你可以传入 --force 标记来强行推送。就像下面一样:
# 小心使用这个命令!
git push --force
它会重写远程的 master 分支来匹配你仓库中 rebase 之后的 master 分支,对于团队中其他成员来说这看上去很诡异。所以,务必小心这个命令,只有当你知道你在做什么的时候再使用。
仅有的几个强制推送的使用场景之一是,当你在想向远程仓库推送了一个私有分支之后,执行了一个本地的清理(比如说为了回滚)。这就像是在说「哦,其实我并不想推送之前那个 feature 分支的。用我现在的版本替换掉吧。」同样,你要注意没有别人正在这个 feature 分支上工作。
本地清理
在你工作流中使用 rebase 最好的用法之一就是清理本地正在开发的分支。隔一段时间执行一次交互式 rebase,你可以保证你 feature 分支中的每一个提交都是专注和有意义的。你在写代码时不用担心造成孤立的提交——因为你后面一定能修复。
调用 git rebase 的时候,你有两个基(base)可以选择:上游分支(比如 master)或者你
feature 分支中早先的一个提交。我们在「交互式 rebase」一节看到了第一种的例子。后一种在当你只需要修改最新几次提交时也很有用。比如说,下面的命令对最新的 3 次提交进行了交互式
rebase:
git checkout feature
git rebase -i HEAD~3
通过指定 HEAD~3 作为新的基提交,你实际上没有移动分支——你只是将之后的 3 次提交重写了。注意它不会把上游分支的更改并入到 feature 分支中。
如果你想用这个方法重写整个 feature 分支,git merge-base 命令非常方便地找出 feature 分支开始分叉的基。下面这段命令返回基提交的 ID,你可以接下来将它传给 git rebase:
git merge-base feature master
交互式 rebase 是在你工作流中引入 git rebase 的的好办法,因为它只影响本地分支。其他开发者只能看到你已经完成的结果,那就是一个非常整洁、易于追踪的分支历史。
但同样的,这只能用在私有分支上。如果你在同一个 feature 分支和其他开发者合作的话,这个分支是公开的,你不能重写这个历史。
用带有交互式的 rebase 清理本地提交,这是无法用 git merge 命令代替的。
保存当前工作状态
此时我在 feature_666 分支,非常聚精会神加持高专注地实现一个功能 666 模块,简直键盘如飞的编写代码~~~ 然后这时,客户反馈出一个 bug , 非常严重,必须立马解决,优先级为 0 !!! 于是,我需要去到 release 分支去 checkout 新的分支去工作了,但是 666 功能还没完成怎么办? 此时我面临着一个选择题:
A:提交后切换,代码保存到分支 feature_666,却产生一个无意义的提交
B:不提交直接切换,然而这个选项根本没人会选。(因为不提交没办法切换分支)
是不是很难选,此时,别忘记还有 C 选项!
C:使用 git stash , 将当前修改(未提交的代码)存入缓存区,切换分支修改 bug ,回来再通过 git stash pop 取出来。
———————————————— 版权声明:本文为CSDN博主「DRPrincess」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_32452623/article/details/76100140
命令:
git stash #将修改储存到暂存区,工作区会删除修改
git stash show #查看刚才暂存的修改
git stash pop #取出修改并删除记录列表中对应记录
git stash list #查看暂存区的所有暂存修改记录
git stash save <message> #给stash 存储的修改起个名字并保存
git stash apply stash@{X} #取出相应的暂存
git stash drop stash@{X} #将记录列表中取出的对应暂存记录删除
标签
命令:
git tag <tag name> #打一个标签
git checkout <tag name> #检出一个标签
git tag -d <tag name> #删除一个标签
远程交互
添加远程仓库(git init方式)
- 初始化
git init
- 添加远程仓库
git remote add <repository name> <url>
git remote add origin xxx.git
- 拉取代码
git fetch
- 将当前分支关联远程分支
git branch -u origin/master
- 关联关系
git merge origin/master --allwo-unrelated-histories
- 合并当前与远程分支
git merge origin/dev
克隆方式(git clone)
- 克隆仓库
git clone url
- 检出分支
git checkout -b <local branch name> <remote branch name> #拉取本地分支与远程分支关联
有关远程分支的命令
git branch -a #查看远程分支
git branch -vv #查看本地分支与远程分支的关联
本地分支与远程分支名称问题
本地分支与远程对应的分支尽量同名,如果不同命会出现问题:
fatal: The upstream branch of your current branch does not match
the name of your current branch. To push to the upstream branch
on the remote, use
git push origin HEAD:dev
To push to the branch of the same name on the remote, use
git push origin HEAD
To choose either option permanently, see push.default in 'git help config'.
可以使用命令提交:
git push origin dev2:dev
或者更改git 配置:
git config --global push.default upstream
操纵远程分支
- 将本地分支推送到远程
git checkout -b feature-branch #创建并切换到分支feature-branch
git push origin feature-branch:feature-branch #推送本地的feature-branch(冒号前面的)分支到远程origin的feature-branch(冒号后面的)分支(没有会自动创建)
- 删除远程分支
git push origin --delete <branch name>
# 或者
git branch -r -d origin/<branch name>
git push origin :<branch name>

